ViCo: Word Embeddings from Visual Co-occurrences
Abstract
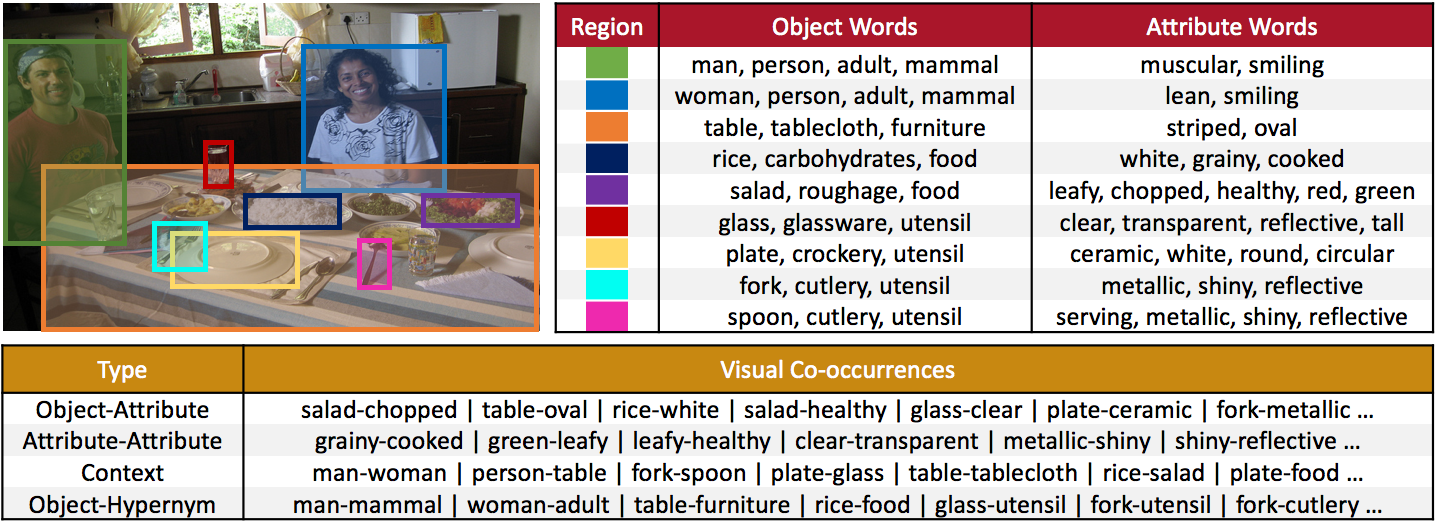
We propose to learn word embeddings from visual co-occurrences. Two words co-occur visually if both words apply to the same image or image region. Specifically, we extract four types of visual co-occurrences between object and attribute words from large-scale, textually-annotated visual databases like VisualGenome and ImageNet. We then train a multi-task log-bilinear model that compactly encodes word “meanings” represented by each co-occurrence type into a single visual word-vector. Through unsupervised clustering, supervised partitioning, and a zero-shot-like generalization analysis we show that our word embeddings complement text-only embeddings like GloVe by better representing similarities and differences between visual concepts that are difficult to obtain from text corpora alone. We further evaluate our embeddings on five downstream applications, four of which are vision-language tasks. Augmenting GloVe with our embeddings yields gains on all tasks. We also find that random embeddings perform comparably to learned embeddings on all supervised vision-language tasks, contrary to conventional wisdom.
Multi-task Log-Bilinear Model
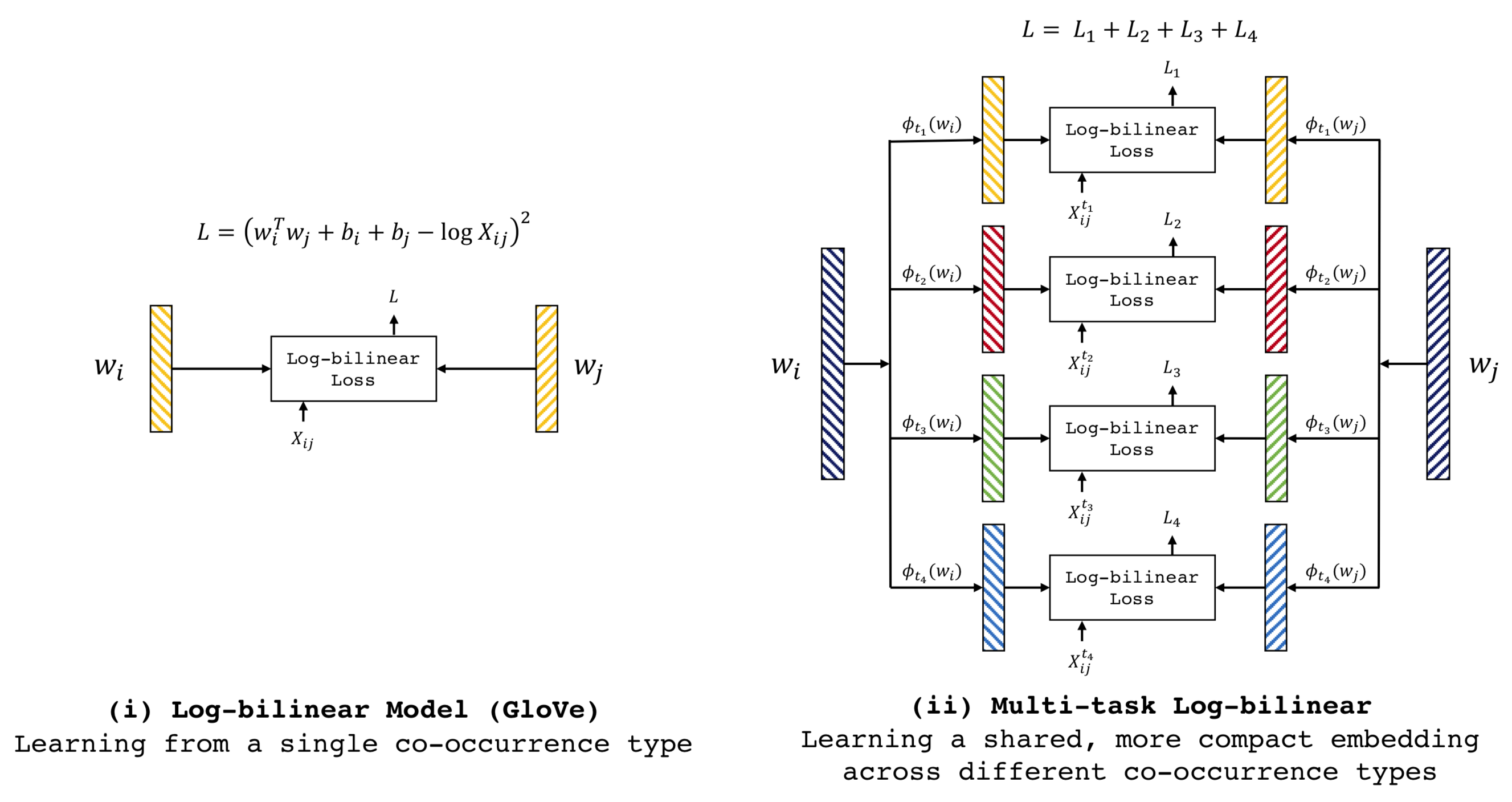
The figure below shows GloVe’s log-bilinear model and our multi-task extension to enable learning from multiple co-occurrences. We show loss computation of different approaches for learning word embeddings \(w_i\) and \(w_j\) for words \(i\) and \(j\). The embeddings are denoted by colored vertical bars. (i) shows GloVe’s log-bilinear model. (ii) is our multi-task extension to learn from multiple co-occurrence matrices. Word embeddings \(w_i\) and \(w_j\) are projected into a dedicated space for each co-occurrence type \(t\) through transformation \(\phi_t\). Log-bilinear losses are computed in the projected embedding spaces.
Results
We refer the readers to the paper for quantitative analysis through unsupervised clustering, supervised partitioning, and zero-shot generalization analysis. But here we would like to highlight our coolest qualitative results!
#1 Modelling multiple co-occurrence types results in a richer sense of relatedness
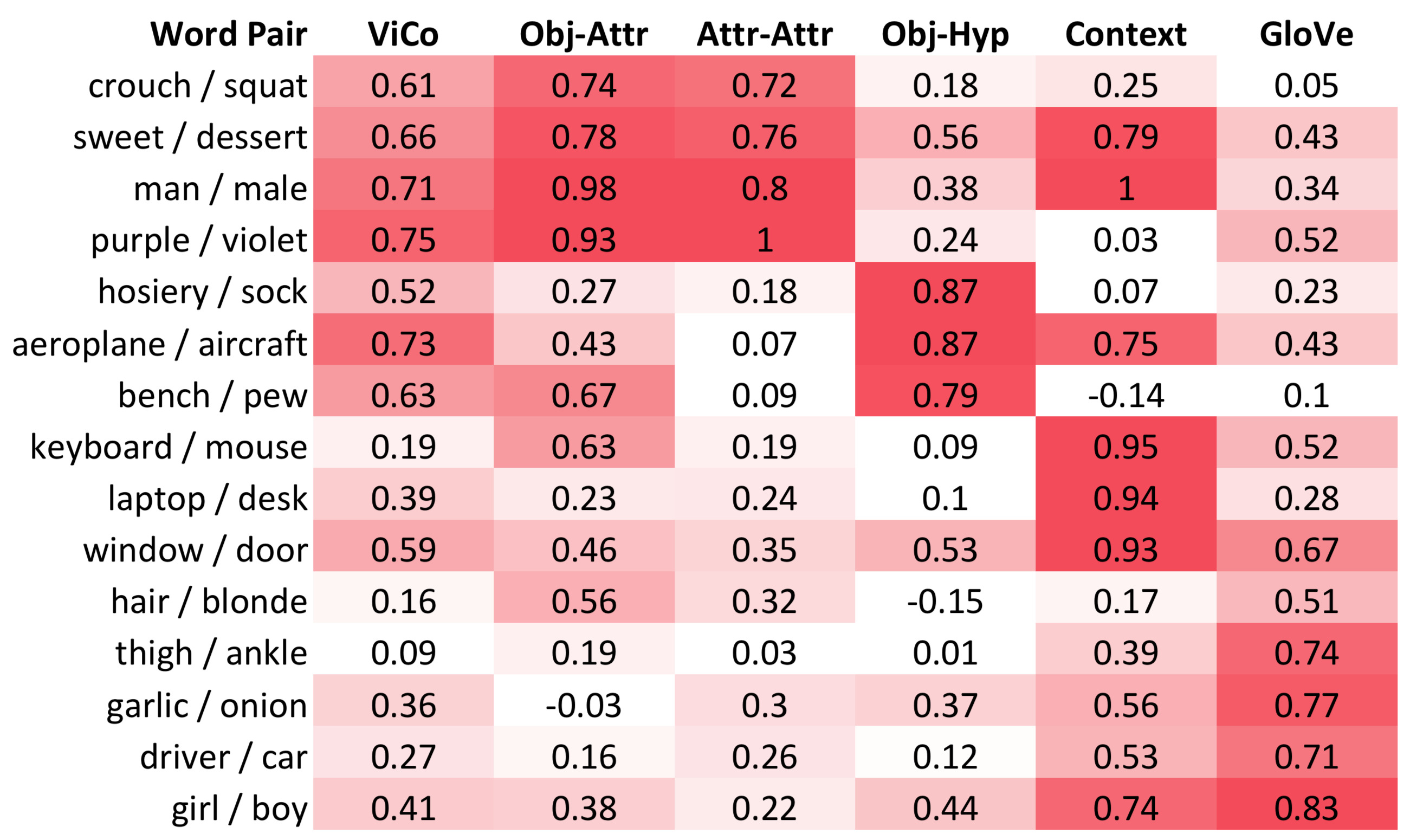
Different notions of word relatedness exist but current word embeddings do not provide a way to disentangle those. Since ViCo is learned from multiple types of co-occurrences with dedicated embedding spaces for each (obtained through transformations \(\phi_t\)), it can provide a richer sense of relatedness. The figure shows cosine similarities computed in GloVe, ViCo(linear) and embedding spaces dedicated to different co-occurrence types (components of ViCo(select)). For example, hosiery and sock are related through an object-hypernym relation but not related through object-attribute or a contextual relation. laptop and desk on the other hand are related through context.
#2 ViCo augmented GloVe results in tighter, more homogeneous t-SNE clusters
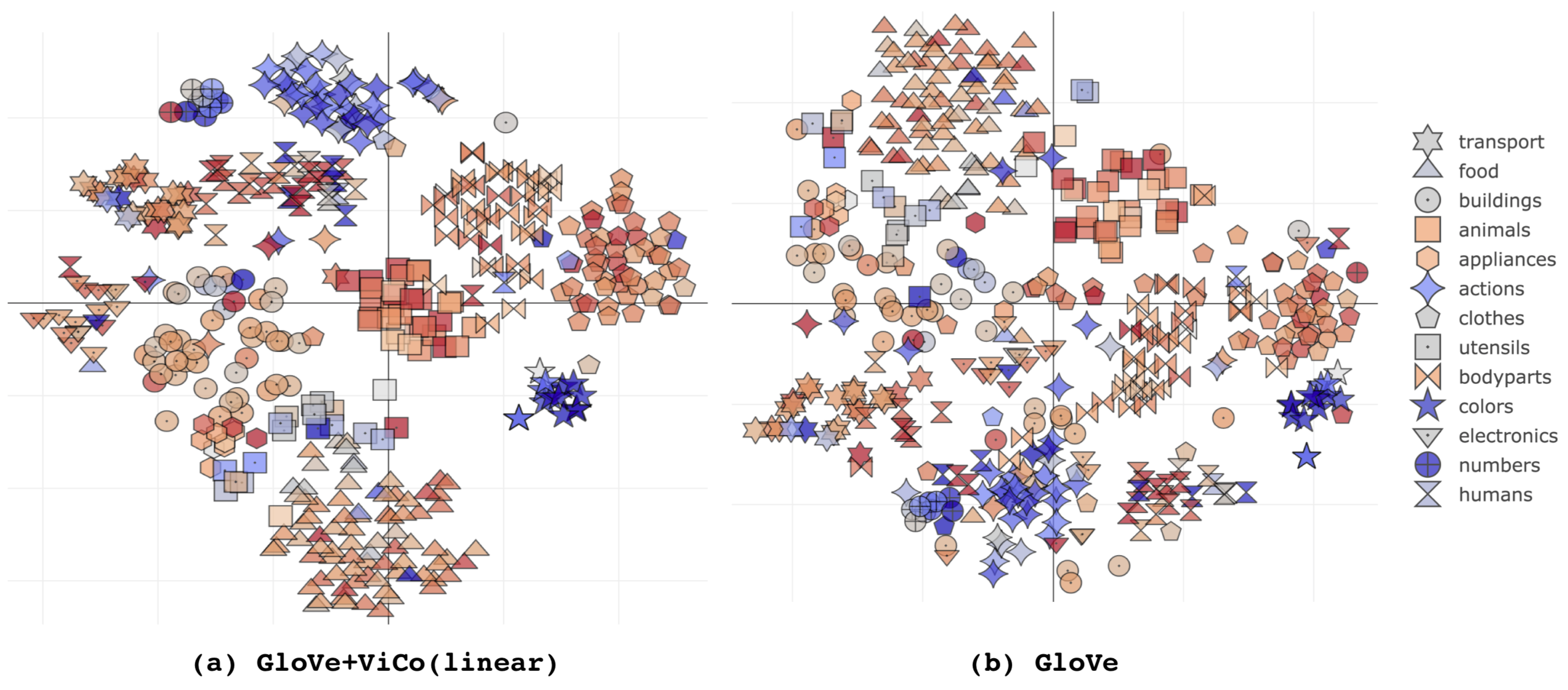
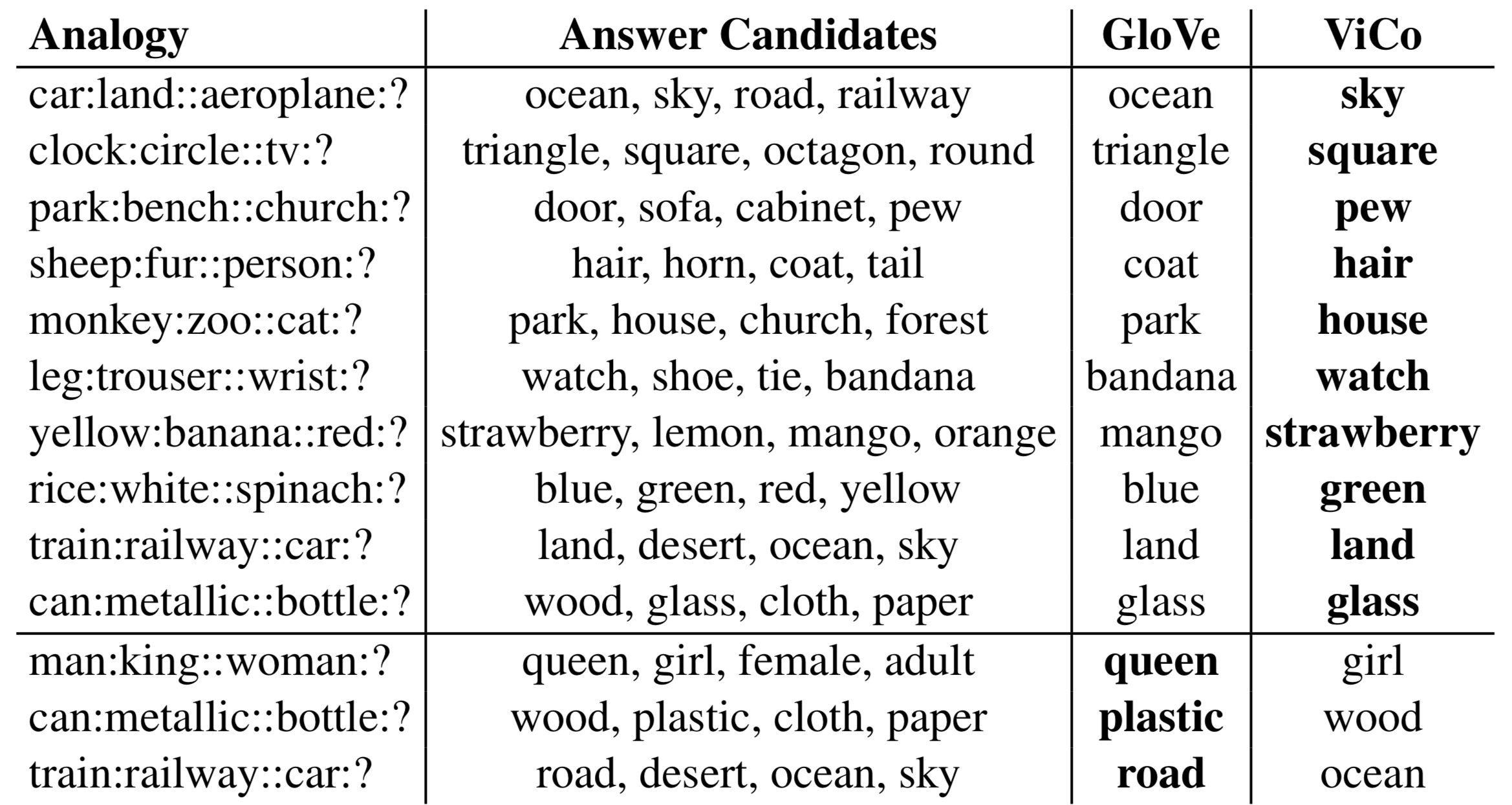
#3 ViCo better captures relations between visual concepts than GloVe
Acknowledgment
This work was partly supported by the following grants and funding agencies. Many thanks!
- NSF 1718221
- ONR MURI N00014-16-1-2007
- Samsung
- 3M
