Publications
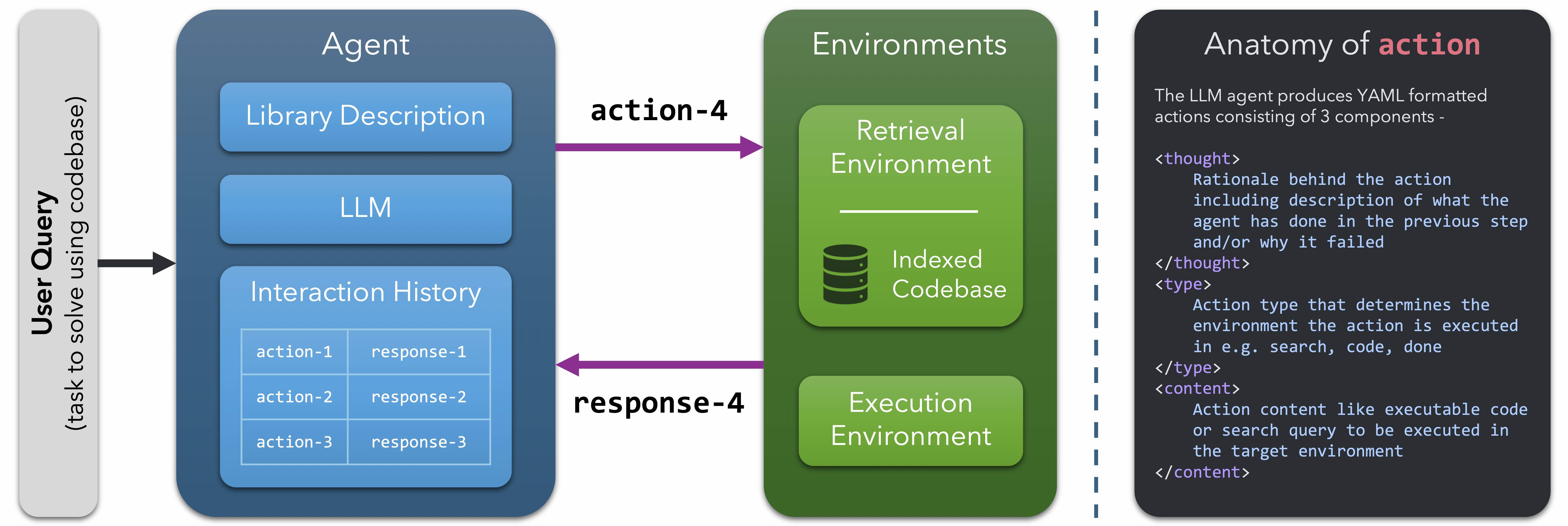
CodeNav: Beyond tool-use to using real-world codebases with LLM agents
arXiv 2024
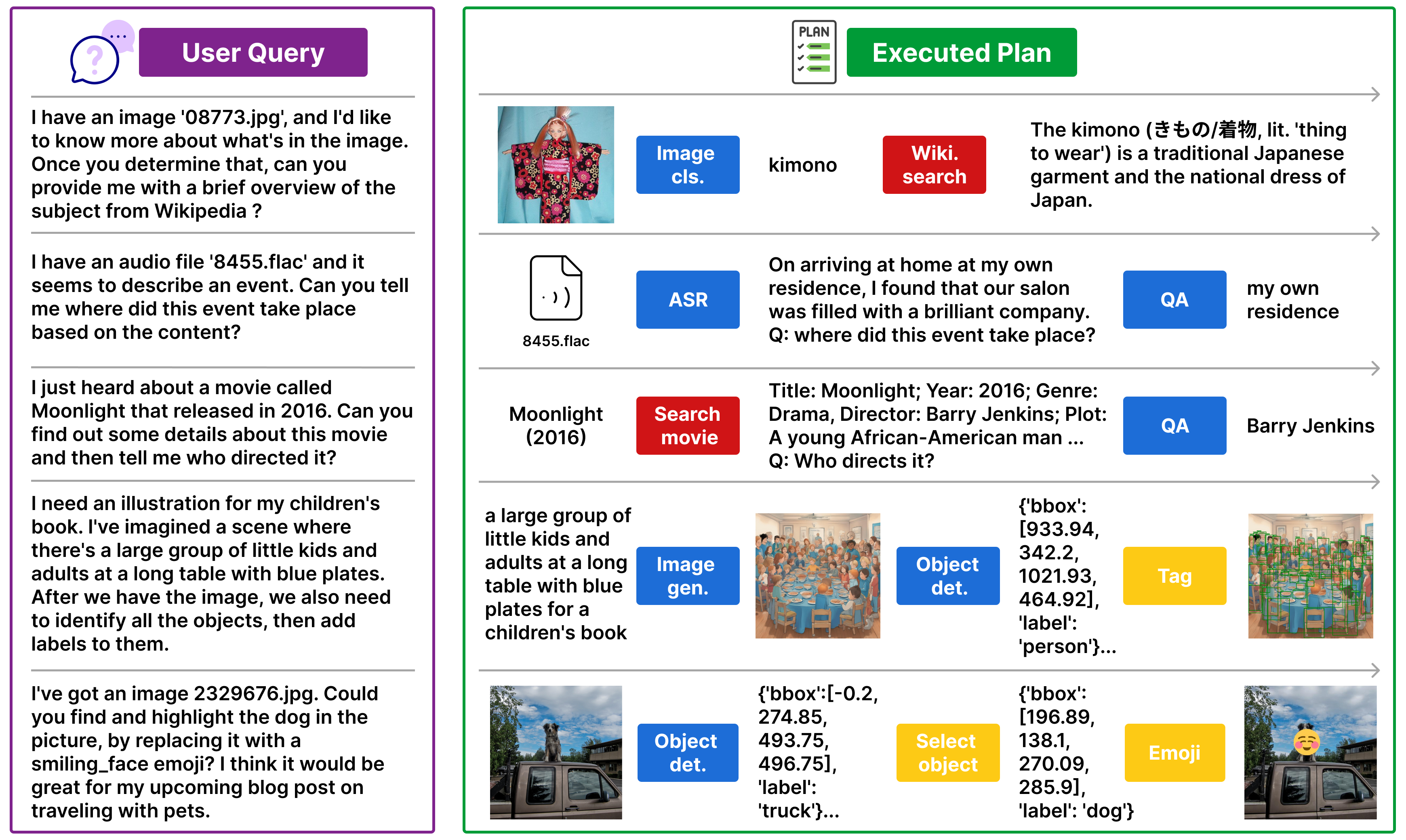
m&m's: A Benchmark to Evaluate Tool-Use for multi-step multi-modal Tasks
arXiv 2024

SPOC: Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
CVPR 2024
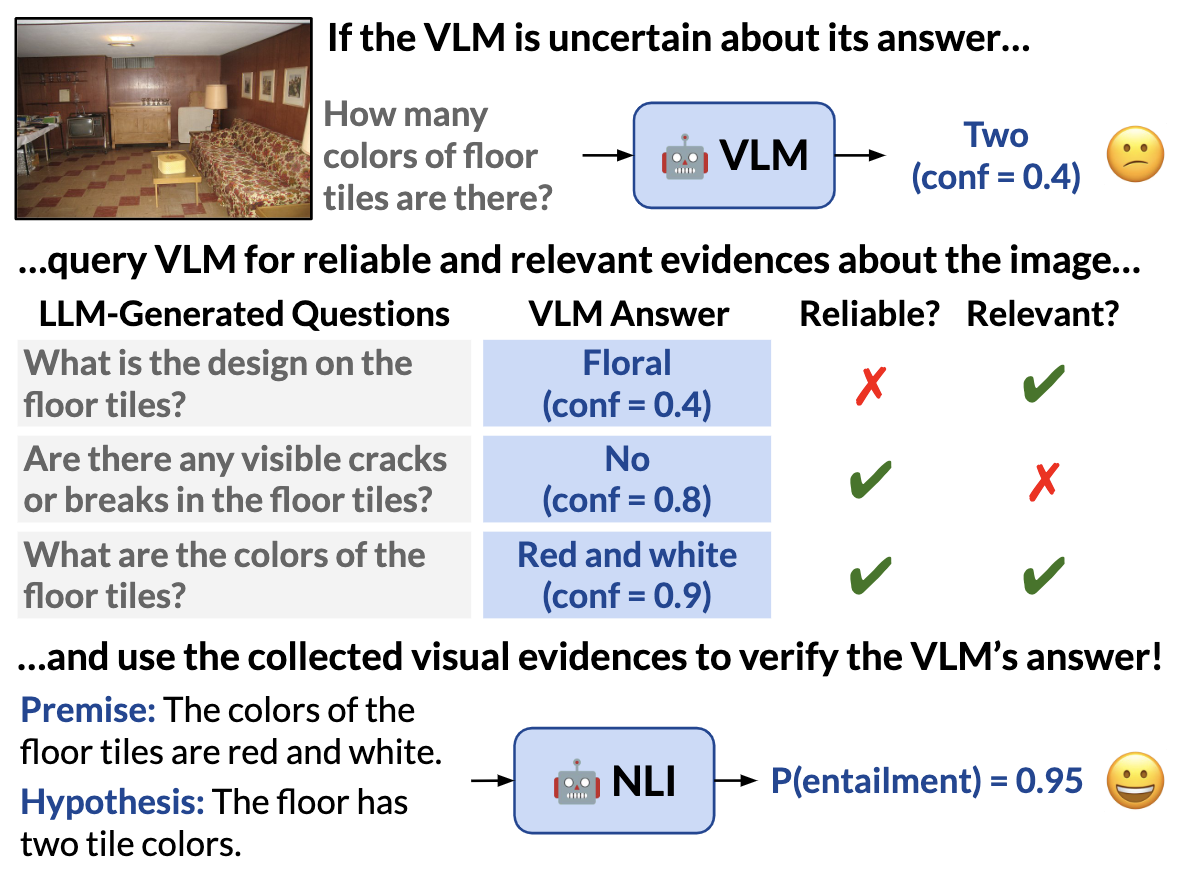
Selective "Selective Prediction": Reducing Unnecessary Abstention in Vision-Language Reasoning
ACL Findings 2024

OBJECT 3DIT: Language-guided 3D-aware Image Editing
NeurIPS 2023

Visual Programming: Compositional visual reasoning without training
CVPR 2023
GRIT: General Robust Image Task Benchmark
arXiv 2022
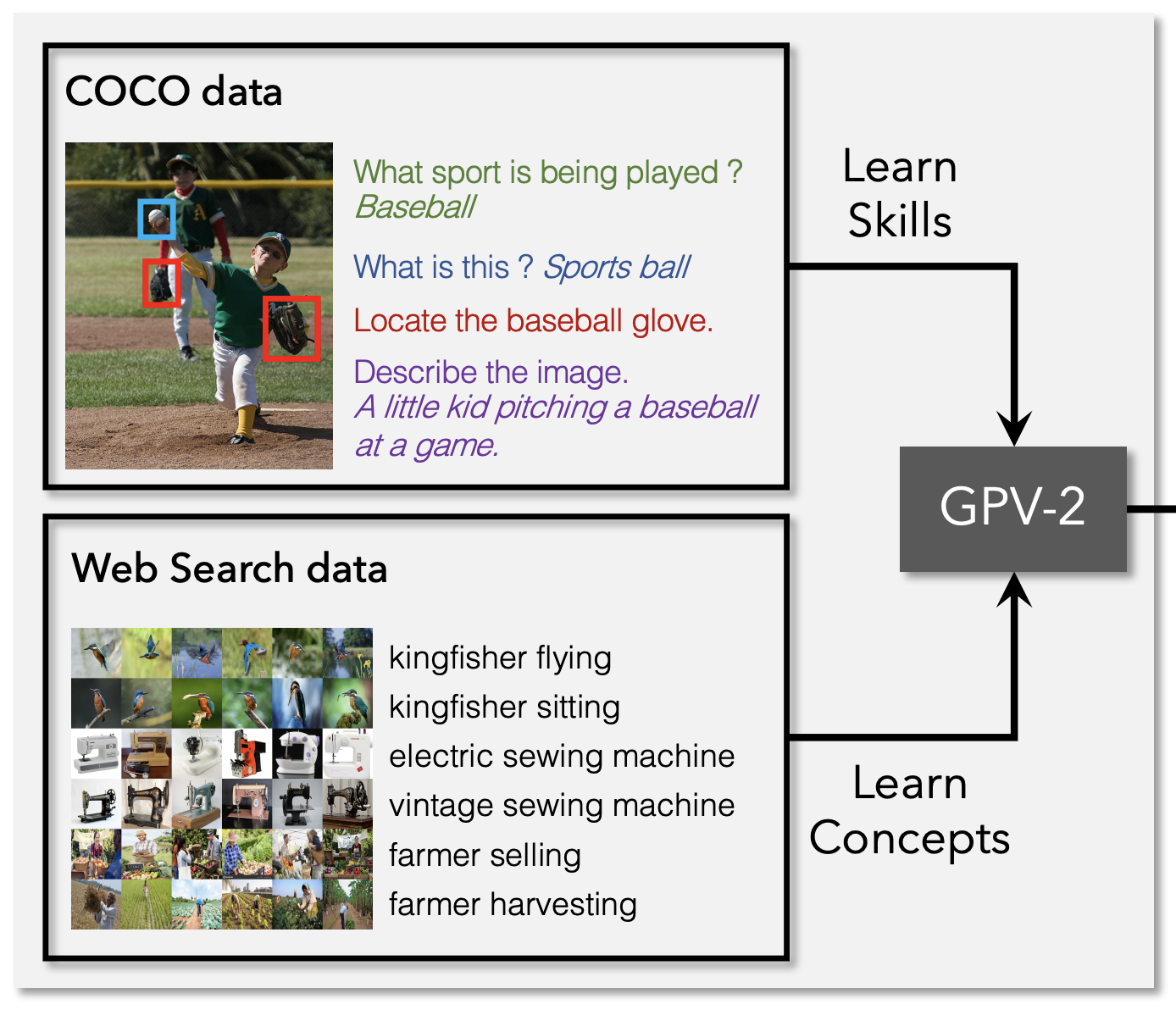
Webly Supervised Concept Expansion for General Purpose Vision Models
ECCV 2022
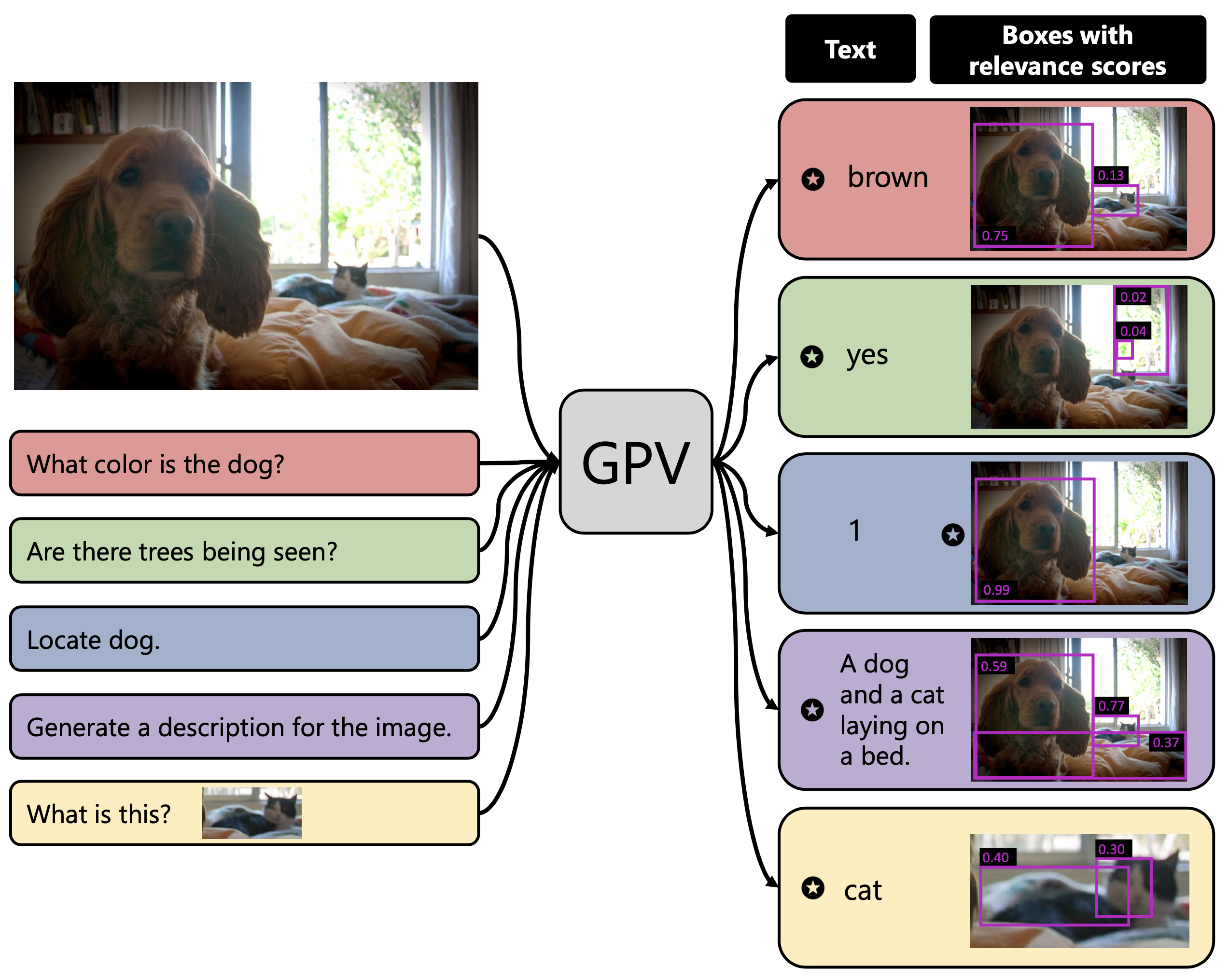
Towards General Purpose Vision Systems: An End-to-End Task-Agnostic Vision-Language Architecture
CVPR 2022 (Oral)
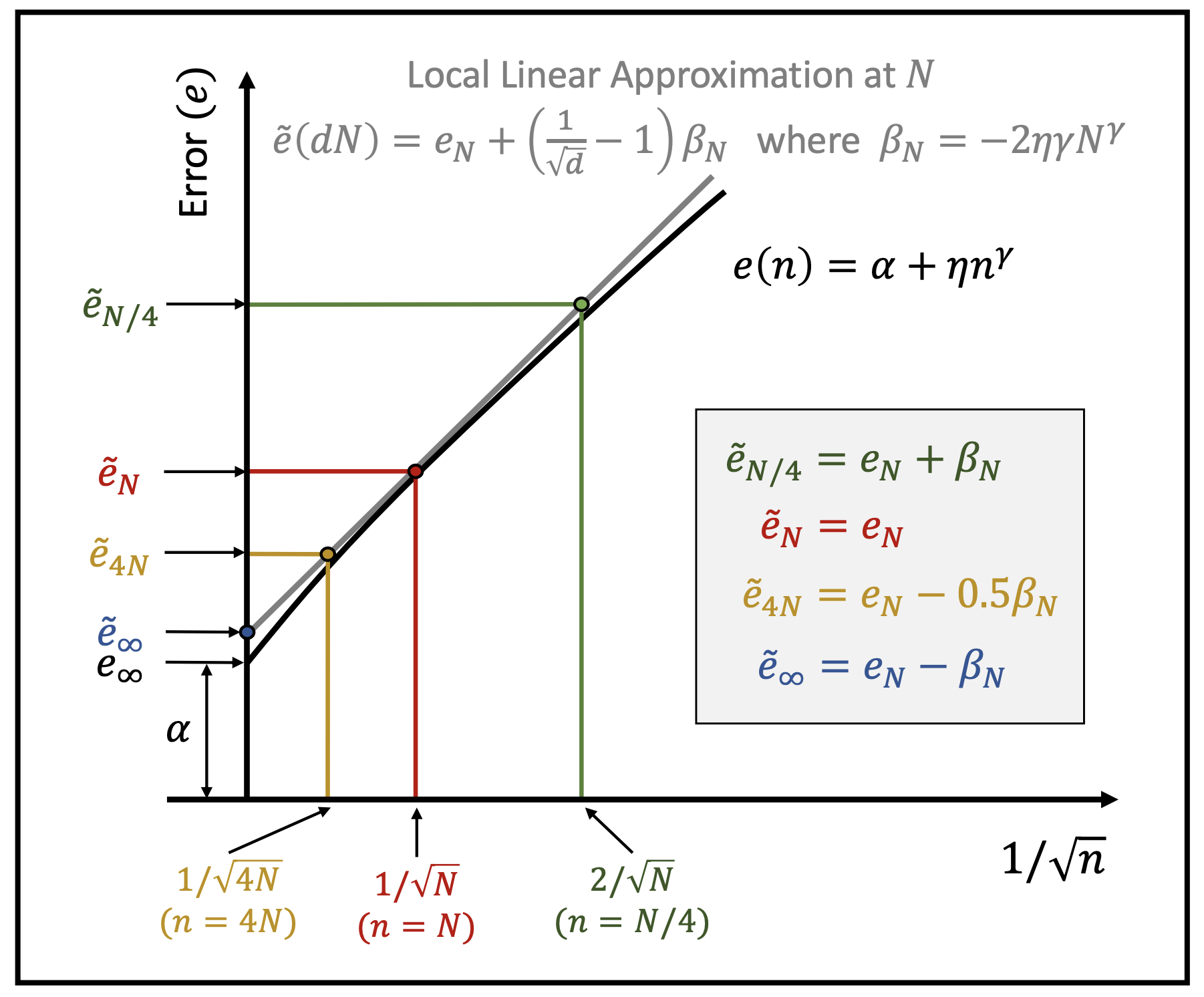
Learning Curves for Analysis of Deep Networks
ICML 2021
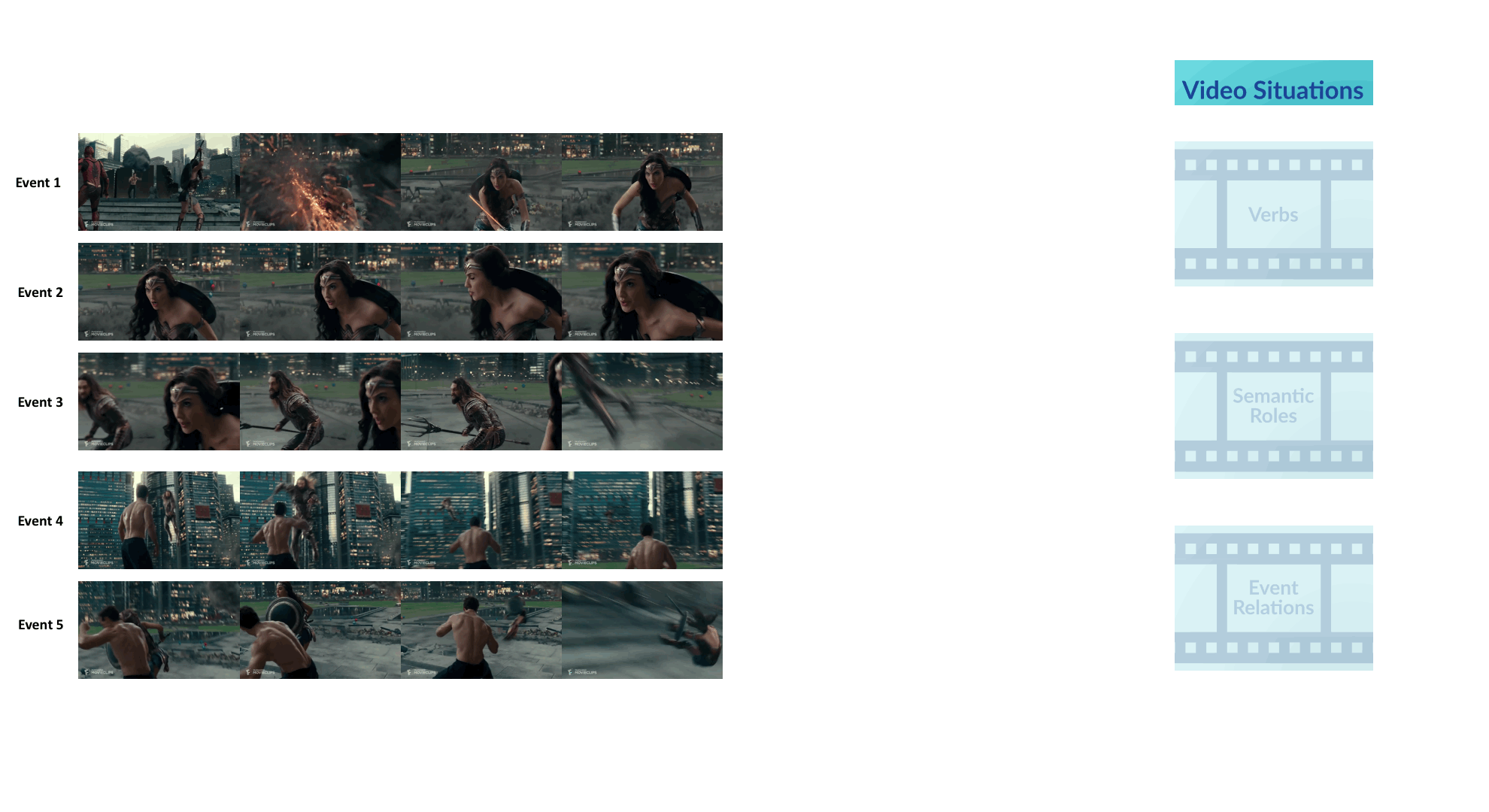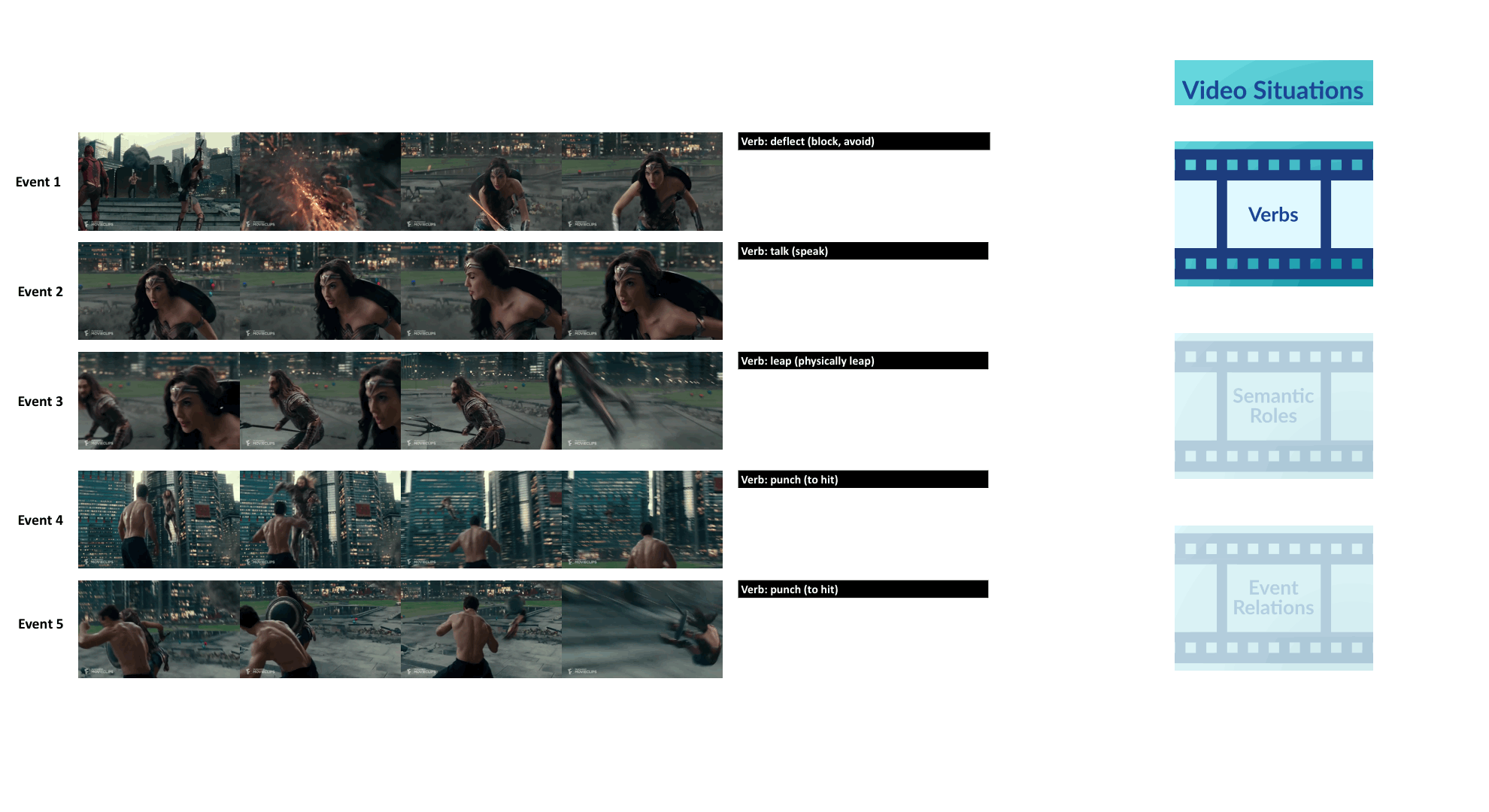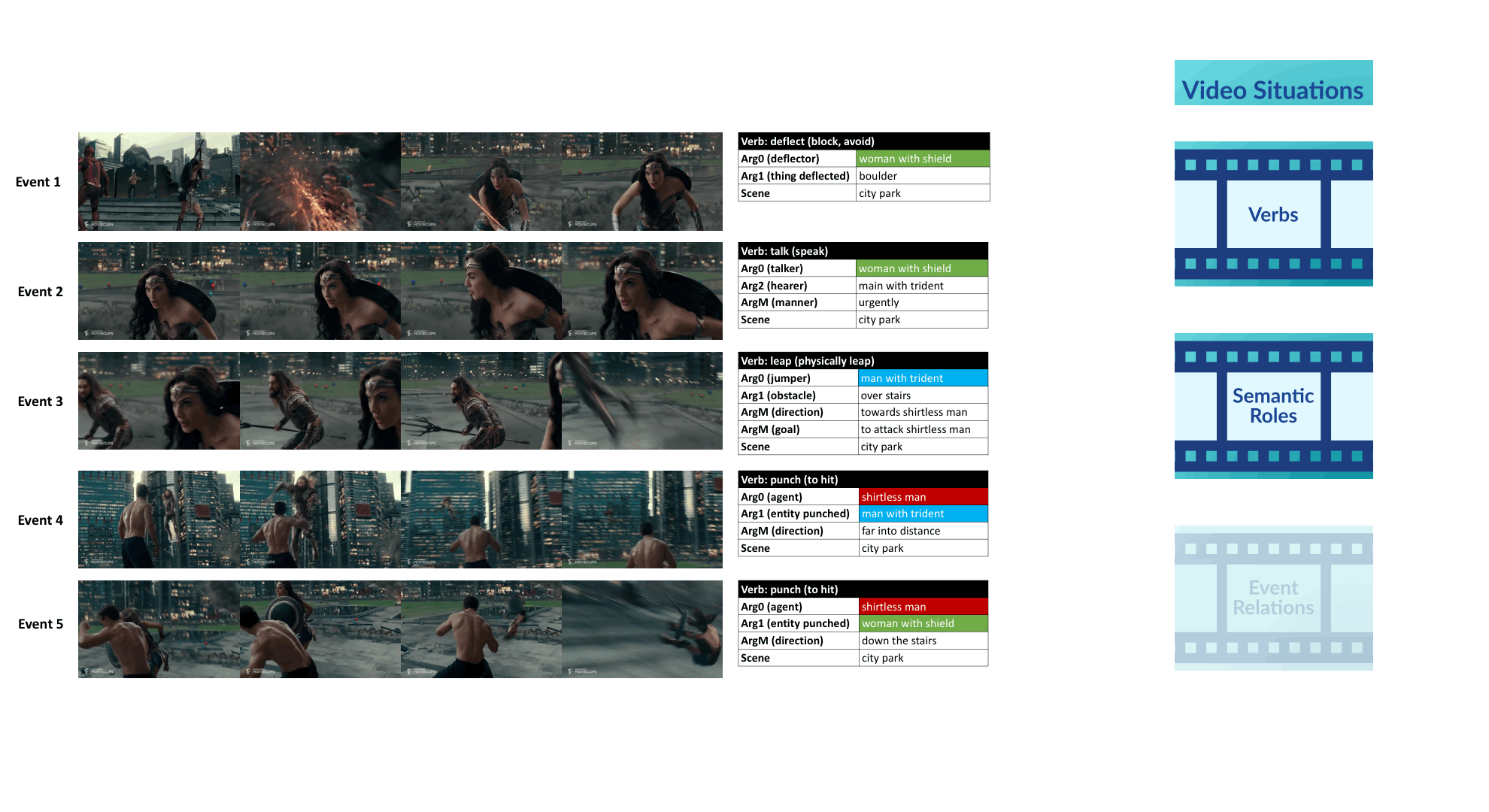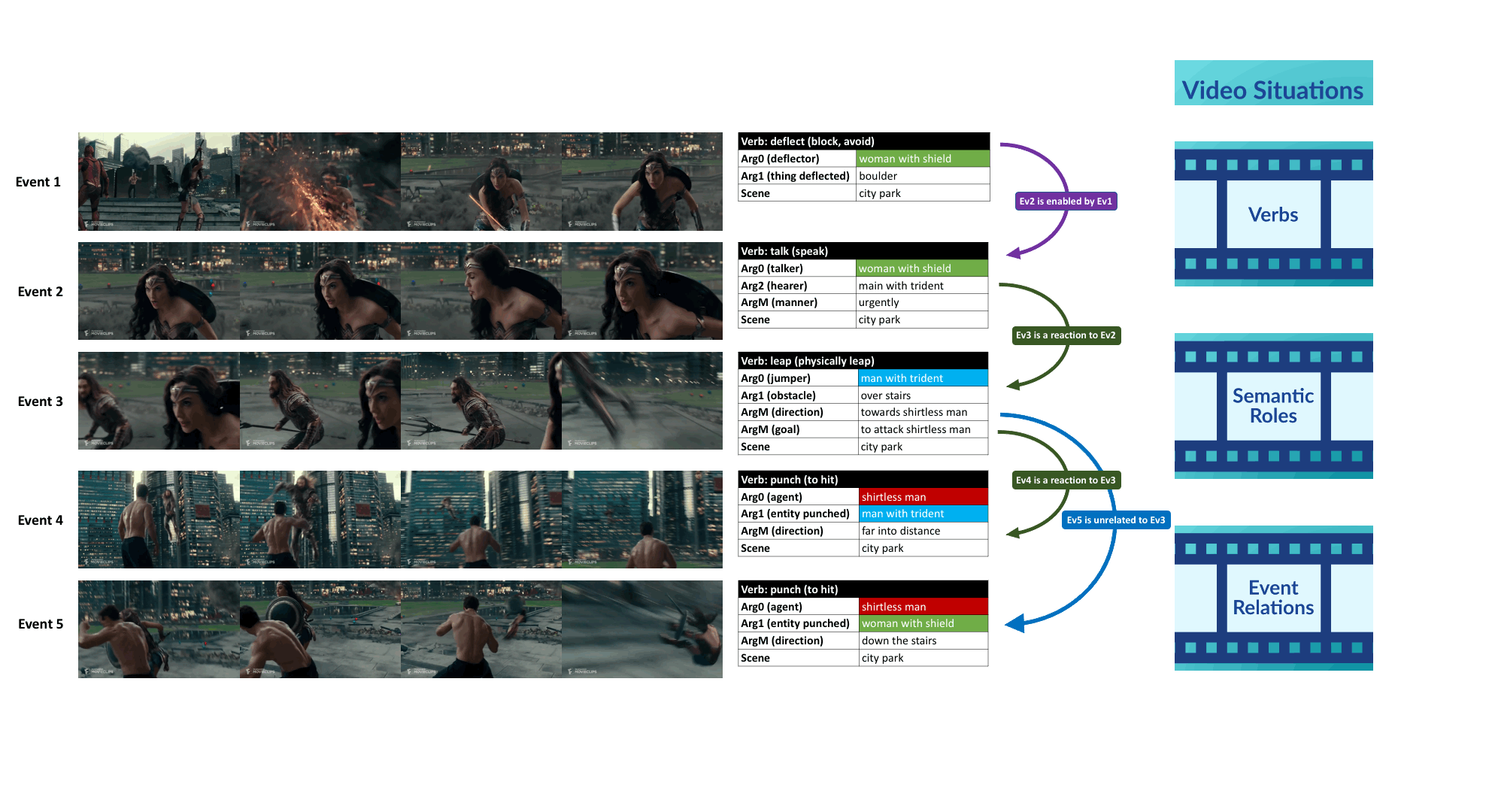
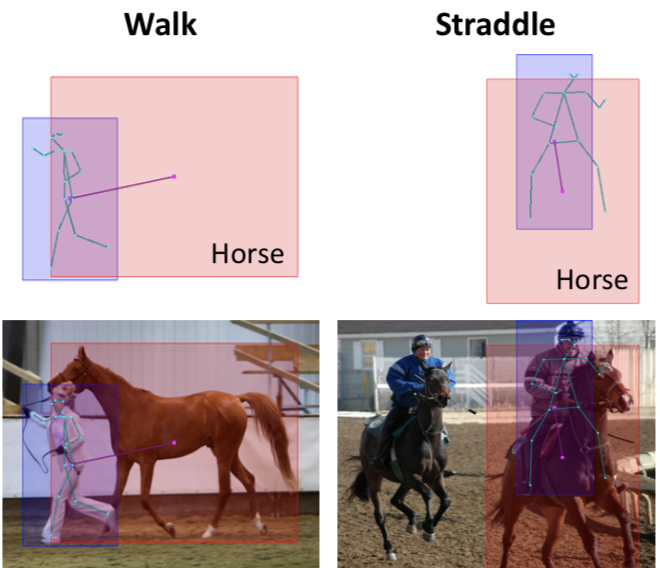
Visual Semantic Role Labeling for Video Understanding
CVPR 2021
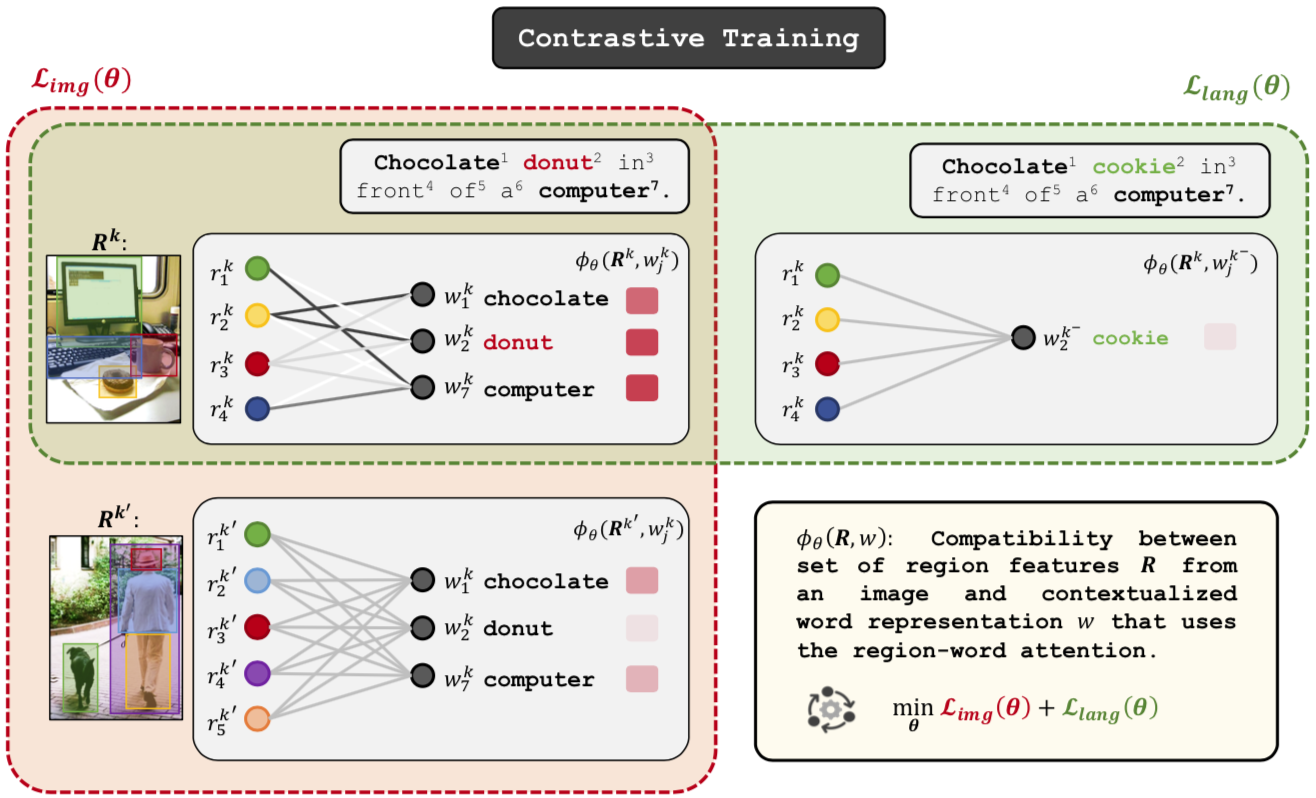
Contrastive Learning for Weakly Supervised Phrase Grounding
ECCV 2020 (Spotlight)

PhD Thesis: Representations from Vision and Language
Thomas M. Siebel Center for Computer Science
University of Illinois Urbana-Champaign
May 2020
University of Illinois Urbana-Champaign
May 2020
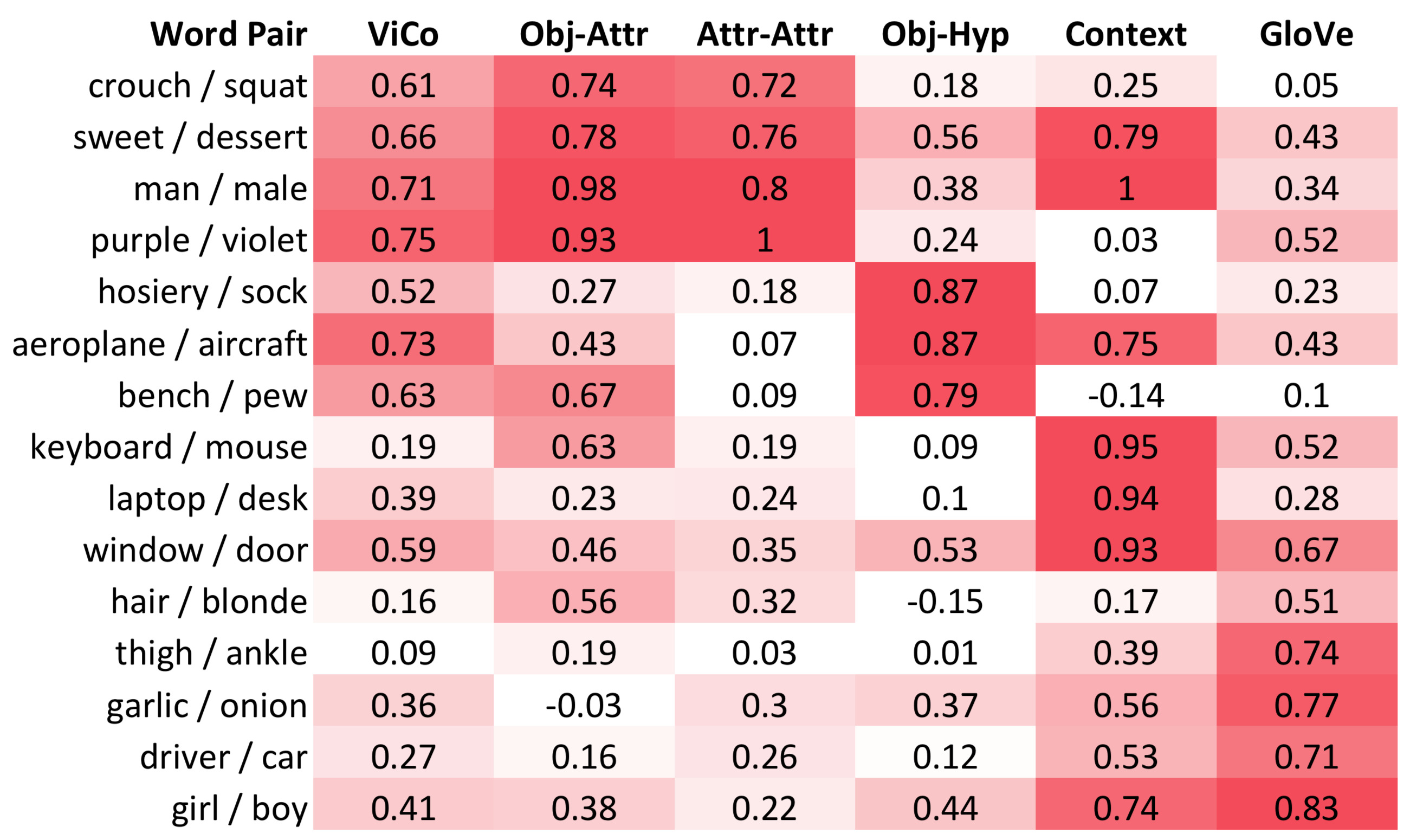
ViCo: Word Embeddings from Visual Co-occurrences
ICCV 2019
No-Frills Human-Object Interaction Detection: Factorization, Layout Encodings, and Training Techniques
ICCV 2019
Imagine This! Scripts to Compositions to Videos
ECCV 2018
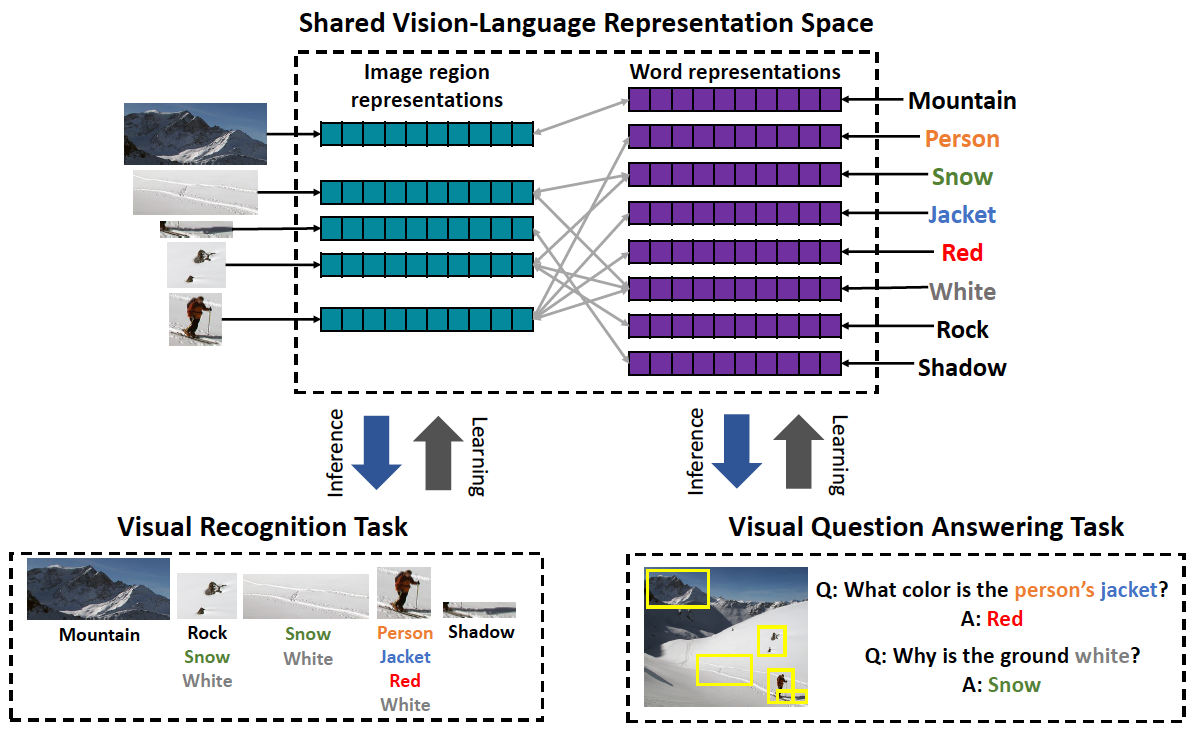
Aligned Image-Word Representations Improve Inductive Transfer Across Vision-Language Tasks
ICCV 2017

3DFS: Deformable Dense Depth Fusion and Segmentation for Object Reconstruction from a Handheld Camera
arXiv 2016
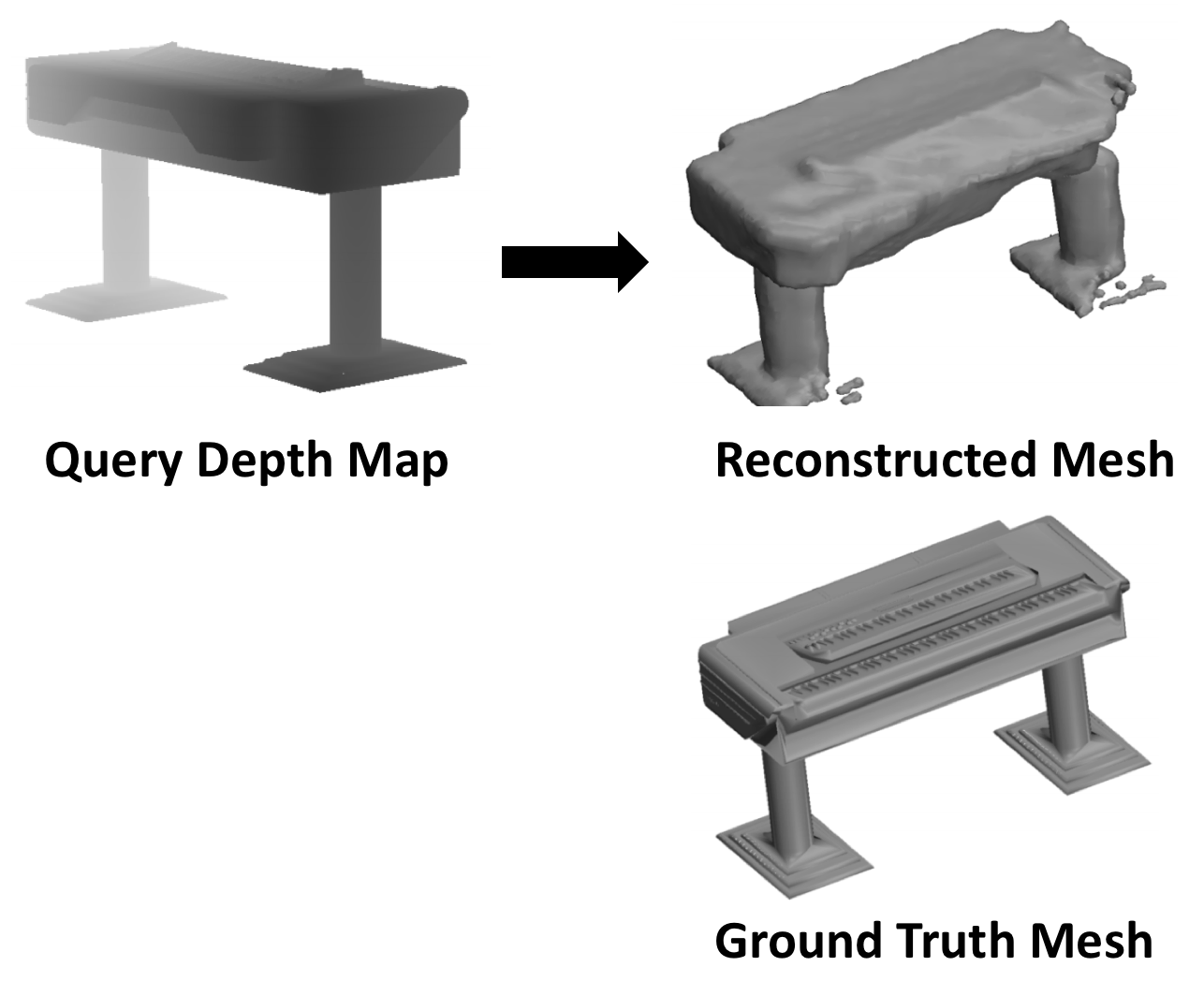
Completing 3D Object Shape from One Depth Image
CVPR 2015
Face Tracking and Recognition with Orientation, Pose and Illumination Variations
Undergraduate Thesis, Department of Electrical Engineeging, IIT Kanpur. 2014
