No-Frills Human-Object Interaction Detection: Factorization, Layout Encodings, and Training Techniques
Abstract
We show that for human-object interaction detection, a relatively simple factorized model with appearance and layout encodings constructed from pre-trained object detectors, outperforms more sophisticated approaches. Our model includes factors for detection scores, human and object appearance, and coarse (box-pair configuration) and optionally fine-grained layout (human pose).
We also develop training techniques that improve learning efficiency by: (1) eliminating a train-inference mismatch; (2) rejecting easy negatives during mini-batch training; and (3) using a ratio of negatives to positives that is two orders of magnitude larger than existing approaches. We conduct a thorough ablation study to understand the importance of different factors and training techniques using the challenging HICO-Det dataset.
Why do we call it a no-frills model?
We make several simplifications over existing approaches while achieving better performance owing to our choice of factorization, direct encoding and scoring of layout, and improved training techniques.
| Key Simplifications |
|---|
| Our model encodes appearance only using features extracted by an off-the-shelf object detector (Faster-RCNN pretrained on MS-COCO) |
| We only use simple hand coded layout encodings constructed from detected bounding boxes and human pose keypoints (pretrained OpenPose) |
| We use a fairly modest network architecture with light-weight multi-layer perceptrons (2-3 fully-connected layers) operating on the appearance and layout features mentioned above |
| No |
| No |
| No |
| No |
| No |
[1] Detecting and Recognizing Human-Object Interactions. CVPR 2018.
[2] Learning to Detect Human-Object Interactions. WACV 2018.
[3] iCAN: Instance-Centric Attention Network for Human-Object Interaction Detection. BMVC 2018.
[4] Learning Human-Object Interactions by Graph Parsing Neural Networks. ECCV 2018.
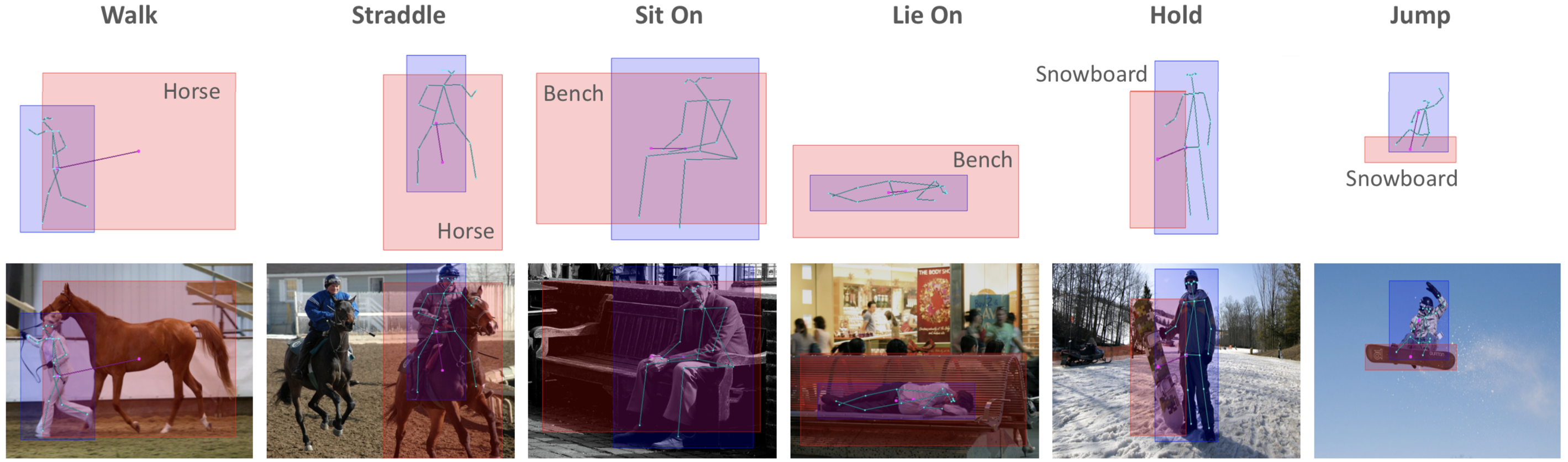
Qualitative Results

Acknowledgment
This work was partly supported by the following grants and funding agencies. Many thanks!
- NSF 1718221
- ONR MURI N00014-16-1-2007
- Samsung
- 3M
